The Unforwarder: How i stopped backing up junk photos
Taming the WhatsApp chaos
I am a huge fan of self-hosting, and one of the things i use is Immich to store precious photos of me and my family. It gives me a bit of relief over paranoia of Google Photos / internet shutting down / hacked / outage stopping me from living in my nostalgia.
A source of lot of these images are shared over messaging services e.g. WhatsApp. If you're an Indian (like me) - you'll be very aware of the influx of forwarded stuff that gets mixed in with actual photos. This includes the infamous "Good Morning messages", which has hilariously crashed Whatsapp couple times now (Whatsapp vs Good Morning). Other things may include screenshots, random memes and what not.
When it comes to backing these up, it involves exporting the Whatsapp Media and painstakingly choosing the photos that i'd want to backup by hand. This is insanely tedious, and the organizational freak in me has long yearned for something that helps me separate the fluff out of the real stuff.
Finding Existing Solutions
I have previously researched on finding existing machine learning models for meme classification, training something like it myself, but to no avail and gave up. If you - the reader, knows of a meme-classification model, please let me know.
Google seems to know this problem, and so one of the only thing that comes close to being useful is the Files by Google app, having sections for cleaning up memes and old screenshots.
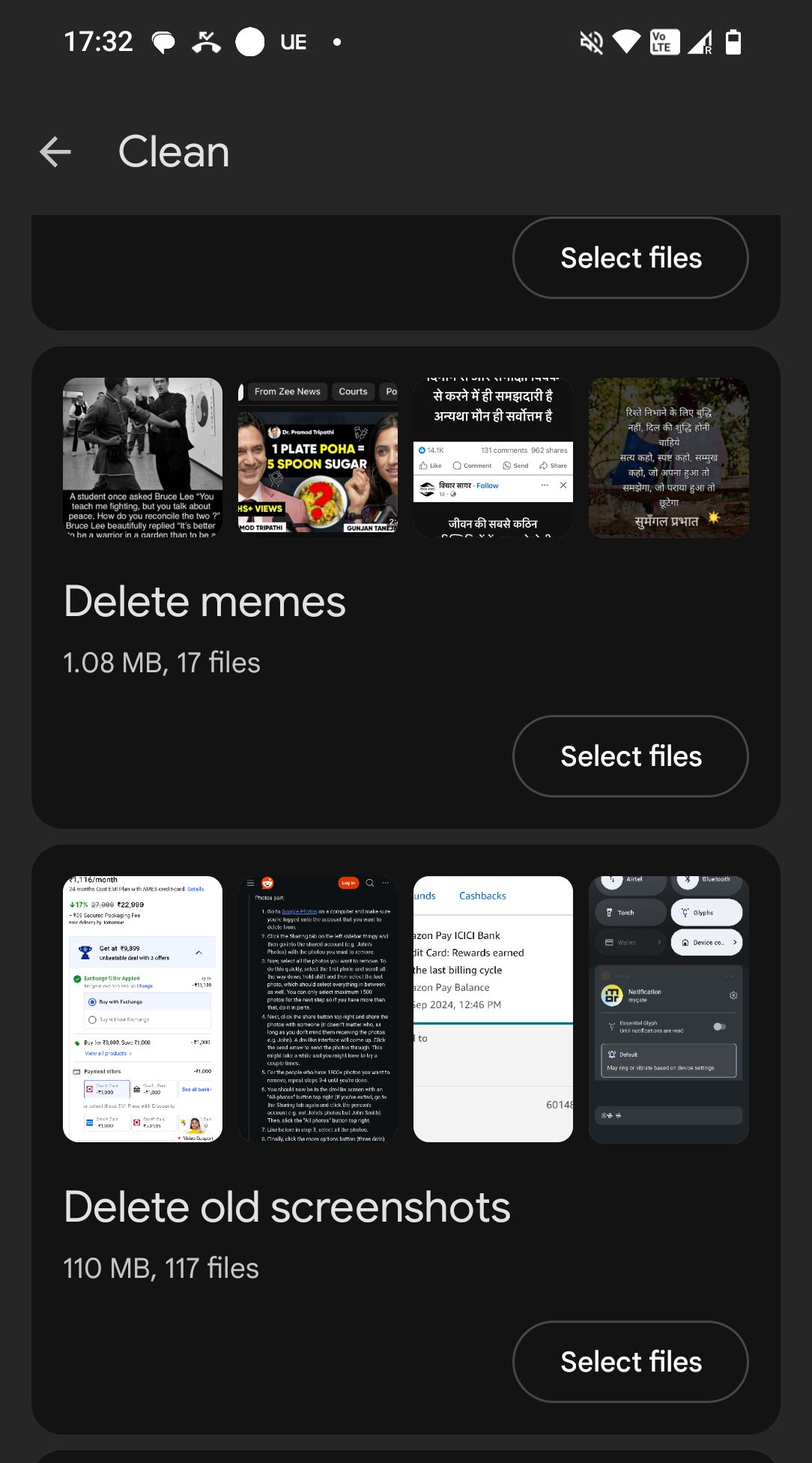
The other helpful thing is built within WhatsApp itself, but solves only a small subset of the problem.
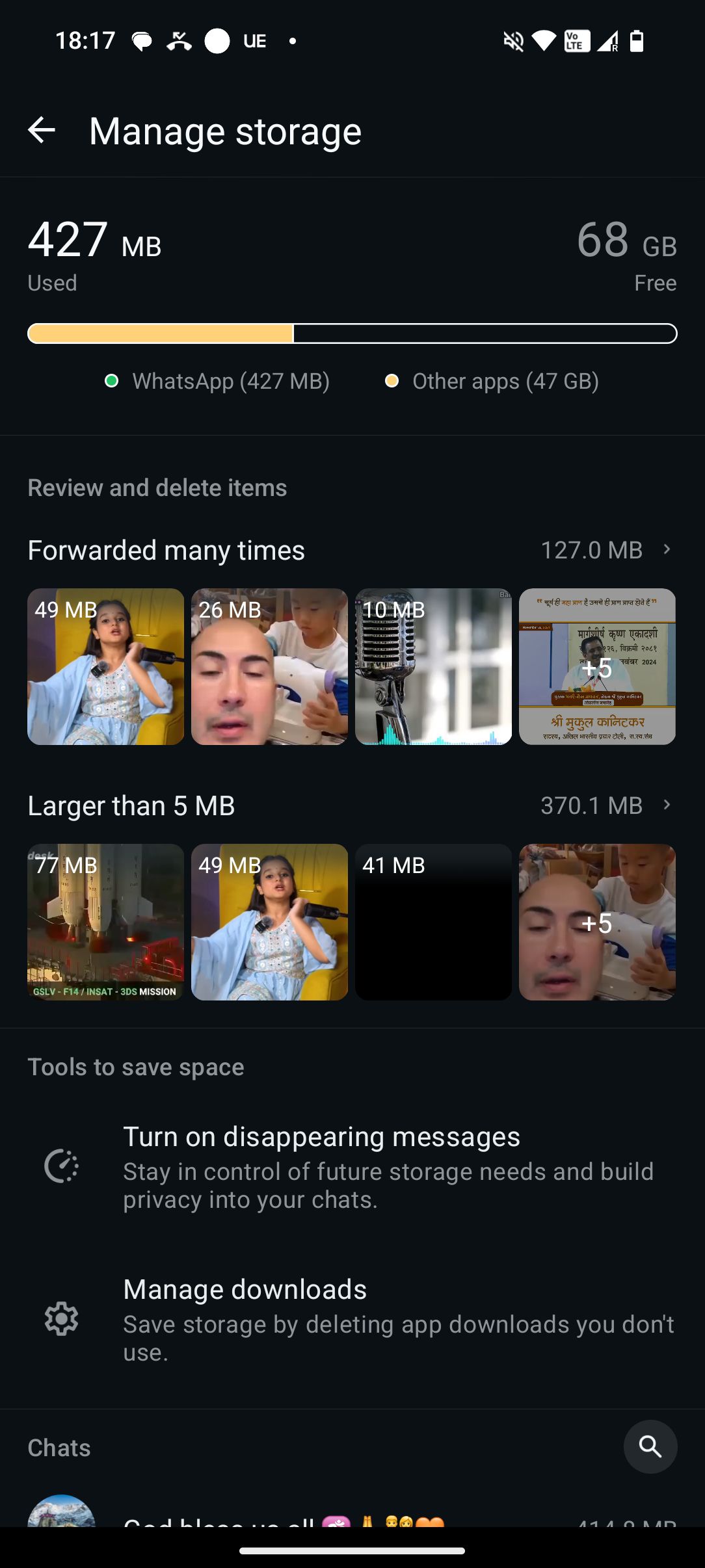
The solution
Hope is rekindled with the plethora of LLM's and vision models that might be just the thing i needed all this time (Thanks, Google).
Thankfully my gaming addiction has got me one good thing - an NVIDIA GPU, on which i can run these fancy multi-modal models. This means all i need is a vibe-coded script, a good prompt, and some time to pass my all images to an ollama instance - make it decide for me what's worth keeping and what is not. The model being local is of paramount importance because i don't want the next generation of models to be trained on the brainrot material i will be feeding them, if i had done so. Also, personal photos - duh.
Choosing a model
For ease of use (available out of the box for ollama) - it boils down to 2 mainstream models that can fit in my RTX 4070 GPU with a meagre 12GB VRAM.
- Gemma-3 (12B) by Google.
- Llama3.2 - Vision (11B) by Meta.
I like the idea of using Meta's model against the problems it has created, so we'll go with #2. (even though the VLM leaderboard recommends otherwise).

Initial Tests
Trying out samples from my "collection" with a simple prompt seems to give promising results.
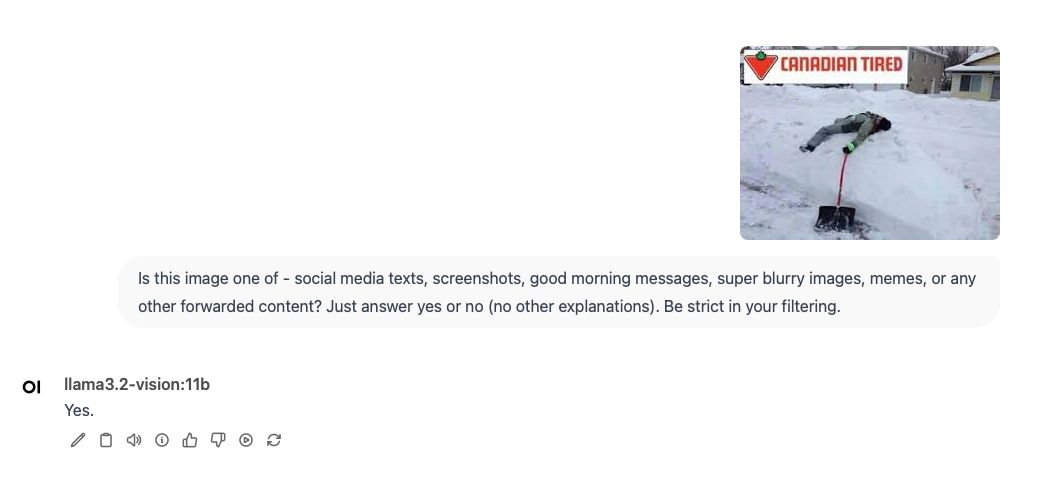
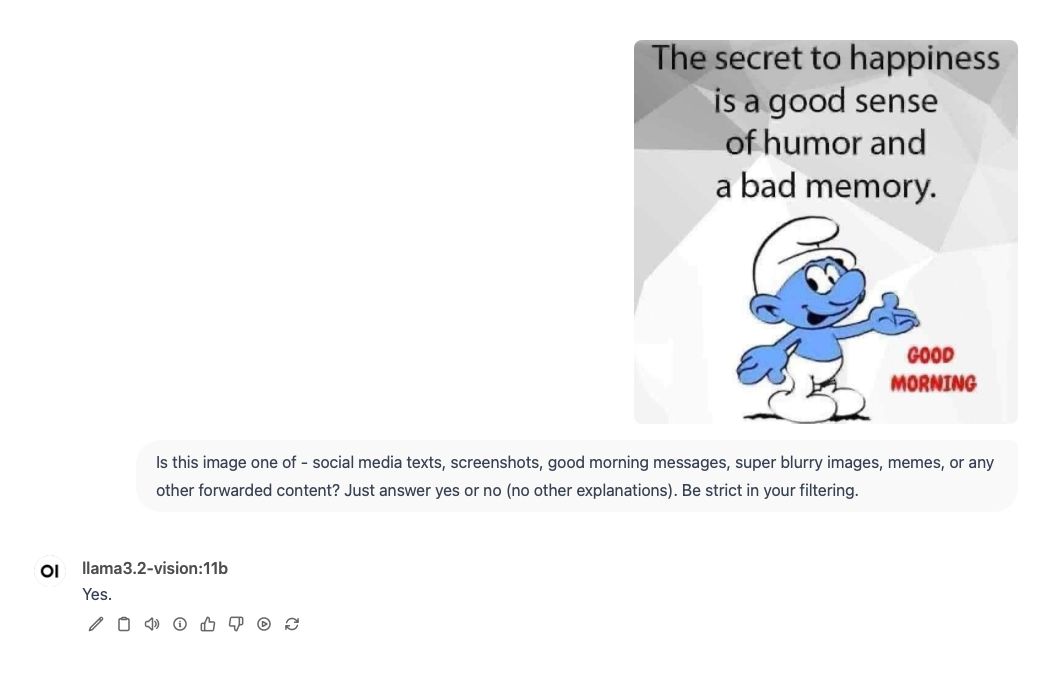
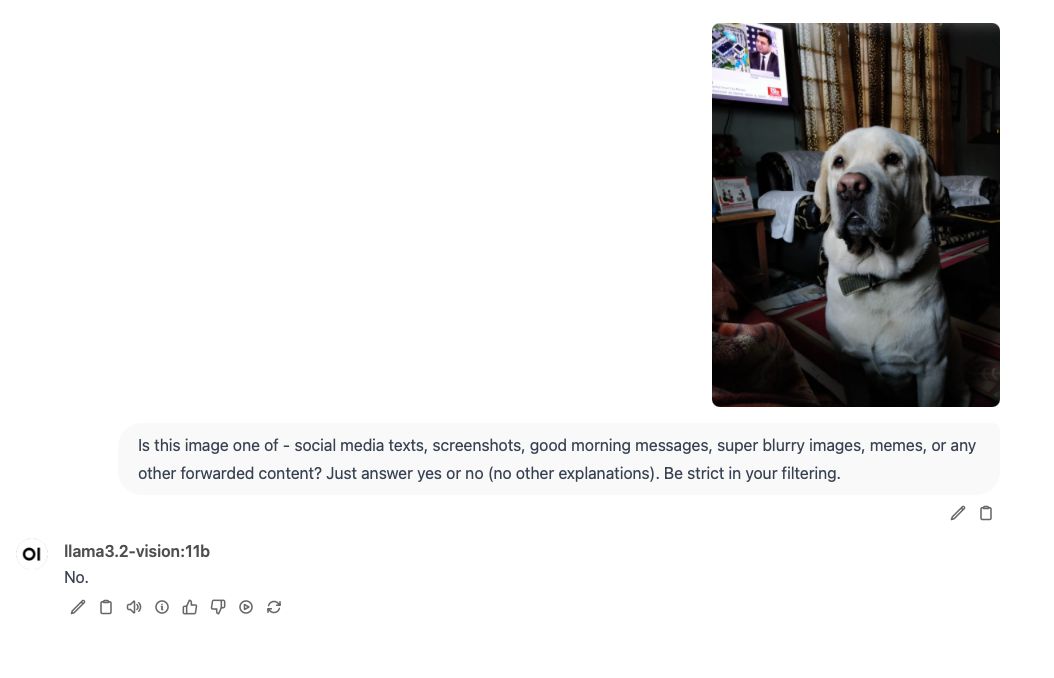
Behold... The Unforwarder
A 60-liner script saving me hours of manual work. Most of it is boilerplate from the Langchain library.
import base64
import os
import shutil
from io import BytesIO
from PIL import Image
from langchain_core.messages import HumanMessage
from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from tqdm import tqdm
# Function to convert PIL Image to base64
def convert_to_base64(pil_image):
buffered = BytesIO()
pil_image.save(buffered, format="JPEG")
return base64.b64encode(buffered.getvalue()).decode("utf-8")
# Create Ollama LLM instance
def create_llm():
return ChatOllama(
base_url="http://localhost:11434", # Change if your Ollama server is elsewhere
model="llama3.2-vision", # Specify your model here
temperature=0,
)
# Create prompt for the LLM
def prompt_func(data):
text = data.get("text", "")
image = data.get("image", "")
content_parts = [
{"type": "image_url", "image_url": f"data:image/jpeg;base64,{image}"},
{"type": "text", "text": text},
]
return [HumanMessage(content=content_parts)]
# Main function to process images
def process_images(source_folder):
# Create save and review folders
save_folder = os.path.join(source_folder, "save")
review_folder = os.path.join(source_folder, "review-n-delete")
os.makedirs(save_folder, exist_ok=True)
os.makedirs(review_folder, exist_ok=True)
# Get all JPG files
files_to_process = [f for f in os.listdir(source_folder)
if f.lower().endswith(".jpg")]
# Initialize LLM chain
llm = create_llm()
chain = prompt_func | llm | StrOutputParser()
# Process each image
for filename in tqdm(files_to_process, desc="Processing images"):
file_path = os.path.join(source_folder, filename)
# Open image
try:
pil_image = Image.open(file_path)
image_b64 = convert_to_base64(pil_image)
# Prepare data for LLM
data = {
"text": ("Is this image one of: social media texts, screenshots, "
"good morning messages, blurry images, memes, or forwarded content? "
"Just answer yes or no."),
"image": image_b64,
}
# Get response from LLM
response = chain.invoke(data)
print(f"File: {filename}, Response: {response}")
# Move file based on response
if response.strip().lower().startswith("no"):
destination = os.path.join(save_folder, filename)
else:
destination = os.path.join(review_folder, filename)
shutil.move(file_path, destination)
except Exception as e:
print(f"Error processing {filename}: {e}")
continue
print("Processing complete!")
# Run the script
if __name__ == "__main__":
# Replace with your folder containing images
source_folder = "/path/to/your/images"
process_images(source_folder)The code is pretty self-explanatory, but in short - it takes a folder of images, passes them through the VLM, and moves them to a "save" or "review-n-delete" folder based on the response. Multiple passes can be made to refine the results, and the prompt can be adjusted as needed.
Full code can be found here.
Next Work
The script is a good start, but there's a lot of room for improvement. Some ideas include:
- Adding more categories to the prompt.
- Implementing a more sophisticated review process.
- An n8n workflow to automate the process of even moving the images to Immich.
Once done, I can finally rest and watch the sun rise on a grateful phone storage.
Updated: